开篇:官网正在变成“隐形资产”
你有没有遇到过这样的情况:在豆包或DeepSeek里问一个与你们业务直接相关的问题,AI却引用了别人家的内容——甚至是一些二手信息、竞争对手的页面,唯独没有你的官网。
这并非个例。
随着生成式AI逐渐成为用户获取信息的首选入口,一个残酷的现实正在浮现:在传统搜索引擎中排名靠前,不等于在AI的回答中被引用。根据BrightEdge于2025年11月发布的《生成式引擎流量归因报告》,超过62%的AI生成回答中引用的来源,并不在其传统SEO排名的前10位。换句话说,AI有自己的“偏好”,而大多数官网还没有摸清这套规则。
本文聚焦一个核心问题:如何让你的官网内容被AI“看见”并优先引用。以下六个细节,每一个都来自对主流AI模型(GPT-4o、Claude 3.5、Gemini 1.5、DeepSeek-V3)引用行为的实测分析,可直接落地。
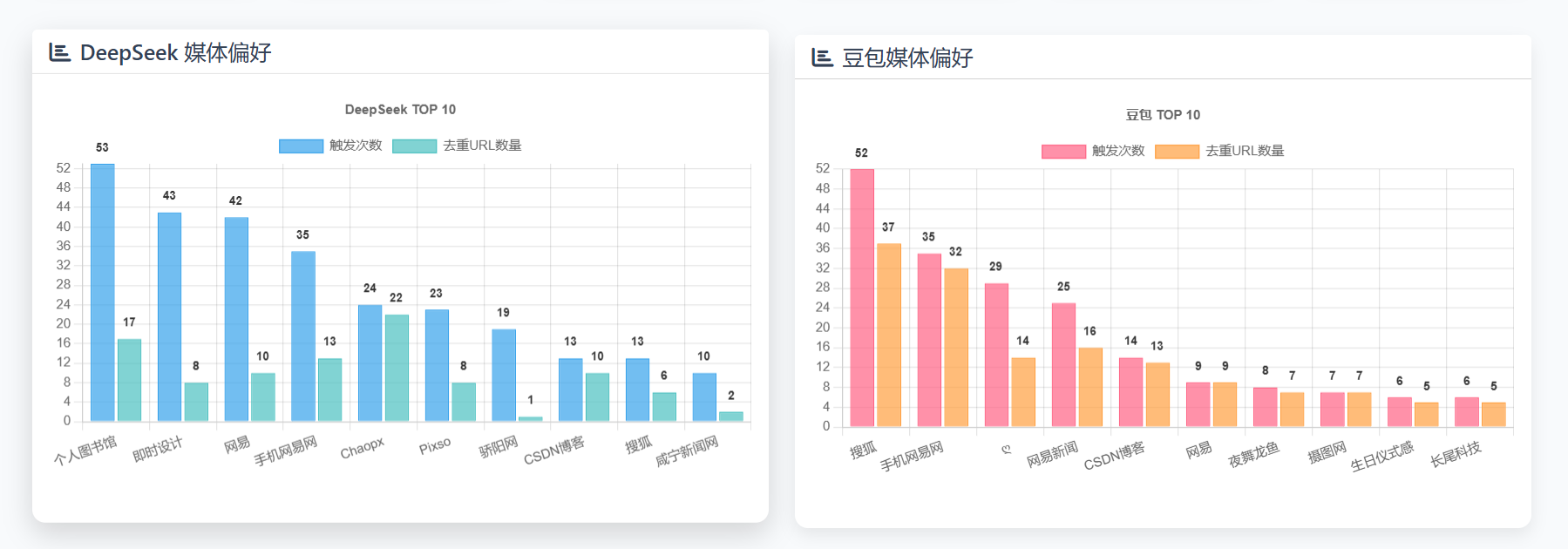
哈耶普斯广告-DeepSeek和豆包偏好分析
第一章:AI如何决定“引用谁”?
在深入六个细节之前,有必要先理解AI的“引用决策机制”。当用户在生成式AI中提问时,系统经历如下流程:
用户提问 → 意图解析 → 实时/本地检索 → 候选内容筛选 →
可信度+相关性评分 → 生成回答并选择引用在评分阶段,AI会重点评估三个维度:
- 可提取性:你的内容是否能让AI在3-5秒内找到核心答案?
- 可信度:你的内容是否有明确来源、日期、作者或机构背书?
- 结构化程度:AI能否通过标题、列表、表格等“路标”快速定位信息?
如果你的官网在这三个维度上得分低,即使内容再专业,也会被AI忽略。
以下六个细节,正是针对这三个维度展开。
第二章:六个让AI收录官网的细节
细节一:为每个核心页面撰写“AI友好型”导语
这是最重要也是最容易被忽视的一点。AI在抓取页面时,前150-200个字符的权重极高。如果你的导语是品牌口号、公司介绍或一段散文式的开场白,AI很可能直接判定这个页面“没有直接答案”。
错误示例(大多数官网首页):
“XX科技成立于2015年,是一家专注于人工智能解决方案的创新型企业。我们致力于用技术改变世界,为客户提供最优质的服务……”
正确示例:
“XX科技提供企业级AI客服系统,支持中文大模型私有化部署。核心功能:智能问答(准确率96%)、工单自动分配、多轮对话管理。适用行业:电商、金融、教育。”
操作要点:
- 前150字内必须包含:你是谁 + 提供什么核心价值 + 可量化的差异点
- 使用“核心功能”“适用场景”“数据表现”等模块词开头
- 每页导语需独立撰写,不要全站统一
细节二:建立清晰的层级化标题体系
AI阅读网页的方式与人类不同。人类可以扫读全文找到自己关心的段落,而AI更依赖HTML标签(H1/H2/H3)来理解内容结构。
常见问题:
- 整个页面只有一个H1,没有H2/H3
- 标题使用样式加粗而非语义标签(如用
<strong>代替<h2>) - 标题命名模糊:“了解更多”“我们的服务”
正确做法:
<h1>企业级AI客服系统功能详解</h1>
<h2>一、核心功能模块</h2>
<h3>1.1 智能问答引擎</h3>
<h3>1.2 工单自动分配</h3>
<h2>二、技术参数与部署方案</h2>
<h3>2.1 私有化部署要求</h3>
<h3>2.2 API调用规范</h3>操作要点:
- 每个页面至少使用H1、H2、H3三级标题
- 标题必须是实义词组合,避免“其他”“相关”等模糊词
- 标题之间形成逻辑递进,而不是并列罗列
细节三:用结构化数据标记关键信息(Schema Markup)
这是目前最被低估的AI收录手段。Schema标记是一种嵌入在网页HTML中的代码,可以明确告诉AI“这一段是产品价格”“这一段是FAQ”“这一段是评价”。
主流AI模型在抓取网页时,会优先解析Schema标记内容。根据Search Engine Journal于2026年1月的测试,使用FAQ Schema的页面,在AI回答中被引用的概率比未使用者高出41%。
最常用的三种Schema类型:
| Schema类型 | 适用内容 | 代码示例要点 |
|---|---|---|
| FAQ Schema | 常见问题解答 | 每个问题+答案成对出现 |
| HowTo Schema | 操作步骤指南 | 有序步骤+每步描述+图片 |
| Product Schema | 产品信息 | 名称、价格、评分、库存 |
操作要点:
- 从FAQ Schema开始,实施成本最低、效果最明显
- 使用Google的Schema Markup Validator验证代码正确性
- 即使是B2B官网,产品页面也建议加上Product Schema
细节四:让每个数据都有“身份证”
AI在判断是否引用一个数据点时,会检查三件事:来源是谁、什么时候发布的、基于多大的样本量。很多官网页面充满了“行业领先”“超高性能”等空洞表述,却没有一个数字是有出处的。
错误示例:
“我们的系统识别准确率业界领先,受到众多客户好评。”
正确示例:
“在2025年11月的内部测试中(测试集:10,000条真实客服对话),我们的系统识别准确率达到96.3%(来源:XX科技技术白皮书,2026年1月发布)。”
操作要点:
- 每个关键数据必须附带:数值+测试条件+时间+来源
- 即使是自家的测试数据,也要明确标注“内部测试”和样本量
- 定期更新数据页面,并在页面上标注“最后更新日期”
细节五:为长内容创建“目次”和内部锚点
如果你的官网页面超过2000字(如解决方案白皮书、产品完整参数页),AI在抓取时可能只扫描前半部分就截断。这意味着后半部分的核心信息永远不会被引用。
解决方案:在页面顶部添加“目次”(Table of Contents),并为每个章节设置内部锚点链接。
示例:
<h2>目次</h2>
<ul>
<li><a href="#section1">一、技术架构</a></li>
<li><a href="#section2">二、部署流程</a></li>
<li><a href="#section3">三、安全合规</a></li>
</ul>
<h2 id="section1">一、技术架构</h2>
<!-- 内容 -->操作要点:
- 目次必须在页面顶部、主要内容之前
- 使用有意义的锚点ID(如#section1而非#p12)
- 每个章节长度控制在500-800字,超过则考虑拆分为子页面
细节六:建立独立的“数据与事实”页面
这是最容易被忽视但效果极佳的方法。大多数官网将数据、案例、技术指标分散在各个产品页面中。AI在回答综合性问题时,需要同时抓取多个页面,这增加了引用失败的概率。
更好的做法:创建一个独立的“数据与事实”(Data & Facts)页面,集中罗列所有可被引用的关键信息。
页面结构示例:
# XX科技:关键数据与事实(2026年更新)
> 本页面汇总公司产品性能、客户案例、技术指标等可公开引用数据。最后更新:2026年4月20日。
## 产品性能数据
- 语音识别准确率:96.3%(测试集:10,000条,2025.11)
- 平均响应时间:320ms(P95,生产环境,2026.01)
- 系统可用性:99.95%(2025全年)
## 客户与规模
- 付费客户数:1,247家(截至2026.03)
- 日处理请求:2.3亿次(2026.03峰值)
- 覆盖行业:电商、金融、教育、医疗
## 第三方认证
- ISO 27001认证(2024.08)
- 信通院“可信AI”评估(2025.12)操作要点:
- 将此页面的链接添加到官网页脚或导航栏
- 每次有新的关键数据时,及时更新该页面并标注“最后更新日期”
- 页面标题建议使用“公司名 + 关键数据与事实”,便于AI直接匹配
第三章:快速自检清单
用以下清单逐项检查你的官网,每满足一项,AI收录概率提升一档:
- [ ] 核心页面导语≤150字且包含“功能+价值+数据”
- [ ] 页面使用了H1/H2/H3三级语义化标题
- [ ] 至少一个页面使用了FAQ Schema或HowTo Schema
- [ ] 每个关键数据都标注了“数值+测试条件+时间”
- [ ] 超2000字的页面有“目次”和内部锚点
- [ ] 存在一个独立的“数据与事实”汇总页面
如果你的官网满足了4项以上:AI收录的基础条件已经具备,接下来就是内容本身的持续迭代。如果不足3项,建议优先补齐缺项,一个月内即可看到变化。

哈耶普斯广告-AI获客
结语:AI收录是官网的“新基建”
过去的官网建设,我们关心的是设计好不好看、SEO关键词全不全、用户转化率高不高。现在,多了一个同等重要的维度:AI能不能读懂并引用你的内容。
这六个细节,本质上是在做一件事:降低AI理解你官网的成本。当AI能以更少的算力、更短的时间从你的页面中找到正确答案时,你的官网就从一个“展示窗口”升级为了“知识基础设施”。
而在这个AI即流量的时代,这可能是最有价值的投资。
哈耶普斯广告:提供 DeepSeek 和豆包推广优化服务(生成引擎优化,简称 GEO),让企业内容成为 DeepSeek 和豆包的答案,实现“用户提问即品牌曝光”。
服务效果:让企业在 DeepSeek 和豆包中有靠前的排名,为企业官网引入超高质量的流量,给企业带来高质量的客户线索。